주키퍼 포레터 단어 를 사용하면 서버 운영중 모니터링을 해야할 때 포레터 단어를 이용해서 할 수 있다. 여기서 포레터 단어(four - letter word)는 위키피디아에서 찾아보니 좀 긴 글자를 4글자로 축약한 것이라고 한다. 우리말로 하면 그냥 줄임말 같은 것 같다. 예를들면 상태메시지 -> 상메, 카카오톡 -> 카톡 이런것 처럼 말이다. 포레터 단어의 주요 목표는 telnet이나 nc와 같은 간단한 도구로 사용할 수 있는 단순한 프로토콜을 제공해서 시스템 상태를 점검하고 문제를 진단하는 것이다. *그런데,, 내가 지금 주키퍼 3.6.2를 사용하는데, 포레터 단어가 거의 먹히지 않는다. 3.6.2 관련 Administrator 문서를 보니까 다음과 같은 글귀가 있다. New in 3.5.3: Fou..
top : 시스템 부하 관련 정보를 수초간격으로 실시간으로 갱신하며 표시해준다. load average : cpu가 처리하는걸 기다리는 작업 개수 load average가 높을수록 과부하가 일어나고 있다는 뜻이다. cpu 코어수 이상이 될 경우 과부하가 일어나고 있다고 보면 될 것 같다. cpu 사용률과 cpu 시간 양쪽이 큰 프로세스는 과부하 원인일 가능성이 높음 과부하 원인인 프로세스는 kill명령어로 종료 하도록 한다. 그런데, cpu사용률이 높지 않더라도 load average가 높은 경우가 있는데, 이러할 경우 메모리가 부족하여 발생하는 경우이다. Swap cpu는 보통 작업 장소로 메인 메모리를 사용하지만 메모리 여유 공간이 부족하면 새로운 작업을 할 수 없다. 그렇게 되면 OS는 메모리에 있..
scp는 네트워크 건너서 파일을 복사할 때 사용한다. scp를 실행하면 우선 scp가 ssh를 호출하고, 그 위에서 ssh 통신 경로를 사용해서 파일을 보낸다. ex) 원격에서 내 서버로 파일 복사하기 scp -r jabel@host:temp/results/ /tmp/ 내 서버에서 원격서버로 파일 복사하기 scp -r /tmp/ jabel@host:temp/results/ 여기서 -r은 recursive의 약자로 하위에 있는 파일들을 모두 복사하도록 해준다.

주키퍼,,, 책을 읽어나가면서 정말 매력적인 녀석이라는 점이 느껴진다. 매력적이게 느껴지는 점은 일단 단독서버로 테스트를 진행중이지만, 설치 및 구성이라던지 API사용등이 간편해서 좋다. 이러한 간편함 뒤에 주키퍼가 어떻게 동작하여서 데이터의 신뢰성, 서버의 가용성등을 보장하는지에 대해 책에 적혀있는데 이에대해 정리를 해 보도록 한다 주키퍼의 내부구조 이번 정리되는 내용은 주키퍼가 사용하는 프로토콜에 대해 간략하게 설명하고 고성능을 제공하면서도 결함을 허용하는 메커니즘에 대한 설명이다. 이 내용은 주키퍼를 사용하는 애플리케이션이 동작하는 방법에 대해 깊은 통찰력을 제공하기 때문에 중요하다. 클라이언트가 서버에 연결해서 작업을 실행하는 동안 주키퍼는 서버의 앙상블로 구성되어 실행된다. 리더는 시퀀서처럼 동..
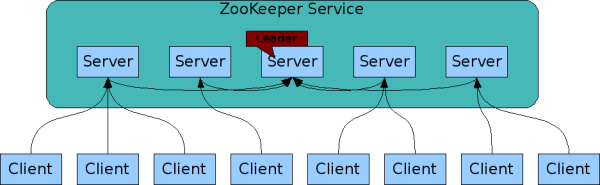
최근 주키퍼 API를 이용해서 집에서 시간이 날때마다 이것저것 해보고있는데, 명령어도 간단해서 너무 유익하다. 그러나, 주키퍼의 설명을 다룬 정리글을 쓰려고 했는데, 깜빡하고 책을 읽기만 하고 정리해둔게 하나도 없어 막막해하던 즈음, 이전에 주키퍼 영문판을 보면서 정리해둔 글을 발견하였다. 그 당시에 책을 읽지 않고 오직 레퍼런스(영문)을 한글로 옮겨적기만 한 글이지만, 정리가 되리라 생각되고, 이렇게 다시읽어보니 그때 이해가 되지 않던 글들이 이해가 되는 느낌이다. 다음은 주키퍼 사이트에서 설명하는 주키퍼의 특징이다. zookeeper.apache.org/

현재 내가 참여한 프로젝트에서는 Kafka라는 하둡에코시스템을 사용하고있다. 뭔가 작성된 코드들과 도식화된 그림들을 보면 카프카가 뭔가 메시지 큐(MQ)의 역할을 한다는 사실을 느낌적인 느낌으로 알 수 있을것 같다. 그러나, 이것은 추측일뿐,, 제대로 공부를 하고싶어서 카프카 쿡북이라는 책을 구입해서 공부를 하려고 하는데, 주키퍼 설정하는 페이지가 나온다. 주키퍼,,, 이건 내가 14년도에 Solr를 공부하려고 하였을 때도 발목을 잡았던 시스템으로 뭔가 분산시스템을 구축하려고 하면 꼭 껴드는 프로젝트로 보인다. 카프카를 계속 공부하려다가,, 주키퍼에 대한 메타지식없이 카프카를 공부하게 될 경우 반쪽짜리 지식이 될 것이라는 판단하에 주키퍼 공부를 시작하였다. 구입한 책은 오레일리사의 주키퍼라는 책인데,,,..
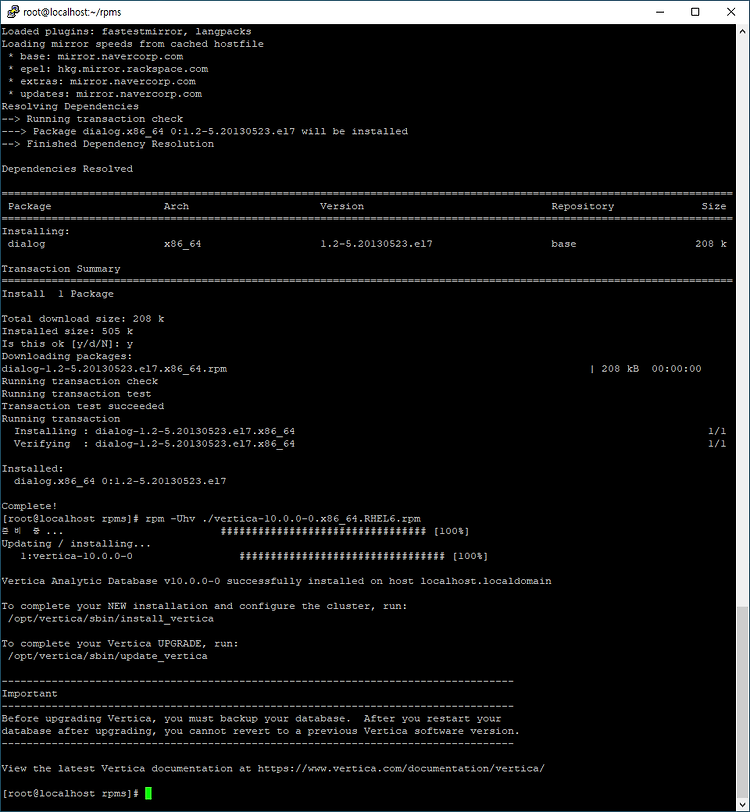
회사에서 대용량 데이터를 다루는 DB를 Vertica로 채택을 관련 프로젝트를 진행중인데 워낙 컬럼기반 DB를 쓰는일은 정말 드문일이다보니 팀원 전체가 처음쓰는 상황이다. 컬럼기반DB에 대해 이번 퇴근길에 집에오면서 대략적이 기능을 보았는데, 적은 수의 컬럼에 대한 분석기능에는 최적화 되어있지만, 많은 로우, 많은 컬럼들을 불러오거나 자주 업데이트가 일어나는 작업에는 적합하지 않다는 사실을 알게 되 었다. 그러한 면에서 과연 이번 프로젝트에 맞는 DB인가 하는 생각이 든다. 어찌되었든,, 쉽지않은 db인 만큼 집에서 많은 시행착오등을 겪어보기 위해 무료버전인 Community Edition을 다운받아 서 이것저것 해보고자 한다. (아니, 당분간은 집에서 버티카에다가 그냥 아무거나 막해봐야겠다. ㅠㅠ) 내..
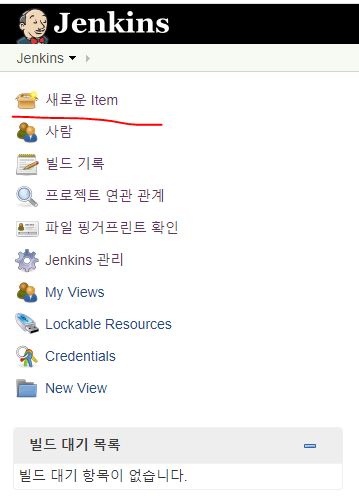
오전중에 개발을 깔짝이다가 수동배포가 불편하여서 제목과 같은 개발set의 프로젝트를 자동으로 배포하는 방법을 리서치를 해보고, 점심을 먹고난 2~3시정도경에 적용을 하였다. 내가 발견한 방법보다 더 우아한 방법으로 배포를 구성할 수 방법이 이미 도처에 깔려있을수도 있다. 그러나 금일 이렇게 이와 관련하여 글을 적는 이유는 내가 평소에 사용하던 수동 배포방법보다 편리하게 배포를 하게 될 수 있게 되었고, 이 환경을 구축하기 위해서 1~2시간의 수고를 들였기에 혹여나 까먹을까봐 글을 쓴다. 원래 술을 먹고 알딸딸해서 글을 안쓰려고 하였으나, 잠이 안오기에 뭔가는 하고싶지만, 코딩은 할 수 없는 상태이기에 오후중의 기억을 되살려 글을 써보고자 한다. 새로운 Item을 클릭한다. Enter an item nam..
회사에서 시스템 운영을 하면서 제목과 같은 현상이 발생하고 말았다. df -h 로 확인을 하였더니 디스크가 100% 차버린 것이다. 그러나, du -sh / , ncdu / 등의 명령을 통해 확인해본 폴더들이 차지하고 있는 용량은 전체의 10%도 사용하고 있지 않았었따. 결론적으로 원인은 파일이 삭제되었지만, 프로세스가 해당파일을 열고있기에 실제 디스크의 용량은 차지하고 있었던 것이다. 이를 확인하기 위해서는 아래의 명령을 통해 확인할 수 있다. lsof | grep "(deleted)"
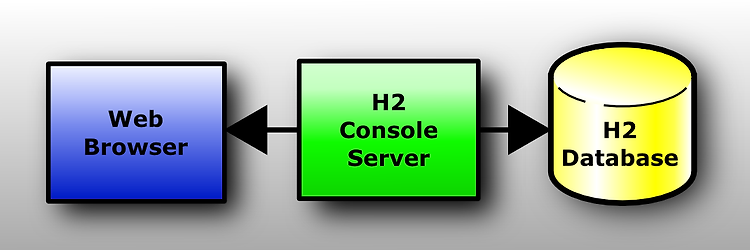
스프링 부트를 공부하면서 H2 데이터베이스를 많이 쓰는것 같다. 많이 쓰는곳은 Test할때 in-memory 데이터베이스를 사용하는 형식으로 사용할 때인데, 특징을 좀 알고 싶어서 해당 사이트에 들어가서 Quick-Start를 간단히 공부를 해보고자 한다. H2 데이터 베이스의 특징 매우 빠르고, 오픈소스이고, JDBC API를 제공한다. Embedded 그리고 인메모리 데이터베이스이다. 브라우저 기반 콘솔 어플리케이션이다. 대략 2MB의 jar 파일 사이즈이다. H2데이터베이스는 임베디드 모드나 서버모드로 사용이 가능하다. 만약 임베디드 모드로 사용하려면 다음의 절차를 따른다. h2*.jar 파일을 클래스패스에 추가한다.(H2는 어떠한 의존관계도 갖지 않는다.) JDBC 드라이버 클래스를 사용한다. :..