
주키퍼,,, 책을 읽어나가면서 정말 매력적인 녀석이라는 점이 느껴진다. 매력적이게 느껴지는 점은 일단 단독서버로 테스트를 진행중이지만, 설치 및 구성이라던지 API사용등이 간편해서 좋다. 이러한 간편함 뒤에 주키퍼가 어떻게 동작하여서 데이터의 신뢰성, 서버의 가용성등을 보장하는지에 대해 책에 적혀있는데 이에대해 정리를 해 보도록 한다
주키퍼의 내부구조
이번 정리되는 내용은 주키퍼가 사용하는 프로토콜에 대해 간략하게 설명하고 고성능을 제공하면서도 결함을 허용하는 메커니즘에 대한 설명이다. 이 내용은 주키퍼를 사용하는 애플리케이션이 동작하는 방법에 대해 깊은 통찰력을 제공하기 때문에 중요하다.
클라이언트가 서버에 연결해서 작업을 실행하는 동안 주키퍼는 서버의 앙상블로 구성되어 실행된다.
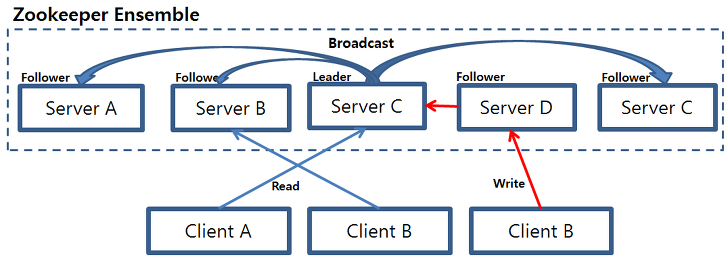
리더는 시퀀서처럼 동작해서 주키퍼에게 전달된 변경사항의 순서를 정의한다. 팔로워들은 장애 상황에서도 상태변경사항을 보장하기 위해 리더가 제안하는 변경사항을 수신하고 투표한다.
리더와 팔로워는 장애 상황에서도 상태변경 사항들의 순설르 보자하는 핵심 구성요소가 된다.
옵저버는 클라이언트가 보낸 요청의 적용 여부를 결정하는 과정에는 참여하지 않는다. 대신 옵저버는 리더와 팔로워가 결정한 변경사항을 학습한다. 이러한 옵저버는 확장성을 위해 사용한다.
요청, 트랜잭션, 식별자
주키퍼 서버는 읽기 요청(exists, getData, getChildren)의 경우 요청을 받은 주키퍼 서버에서 처리한다.
주키퍼 상태를 변경하는 요청(create, delete, setData)은 리더로 전달된다. 리더는 트랜잭션이라고 불리는 상태 변경 사항을 생성해 요청을 실행한다.
요청을 클라이언트에서 시작된 작업을 나타내는 반면 트랜잭션은 주키퍼 상태를 변경하는 단계들로 구성돼 요청의 실행 결과를 적용한다.
주키퍼 앙상블은 적통적인 RDBS에서 제공하는 롤백 메커니즘이 없다. 대신 주키퍼는 각 트랜잭션의 단계들이 다른 트랜잭션과 간섭되지 않도록 한다.
트랜잭션은 멱등원(연산을 여러번 적용하더라도 항상 같은 결과가 나오는 성질)이다. 따라서 동일한 트랜잭션을 두 번 적용할 수 있고 동일한 결과를 얻게 된다. 매번 동일한 순서의 트랜잭션을 적용하는 한, 트랜잭션은 여러번 적용해도 동일한 결과를 얻을 수 있다. 장애 복구시 유용하다.
리더가 트랜잭션 생성시 zxid라는 식벼자를 부여해서 트랜잭션을 구별해, 리더가 정한 순서대로 서버의 상태에 적용될 수 있게 된다. 서버들은 새로운 리더를 선출시 zxid를 교환함으로써 가장 최근 zxid를 갖고 있으면서 결함없는 서버를 찾게 된다.
zxid는 long 정수이고, 이는 두 부분으로 구성된다.
zxid = 에픽(epoch) + 카운터(counter)
리더선출
리더는 앙상블에 의해서 선출되고 앙상블로부터 계속해서 지지를 받는다. 리더는 상태를 변경하는 클라이언트의 요청에 대해 순서를 매긴다.
리더의 요청처리 과정
- 요청을 트랜잭션으로 변환
- 팔로워에게 리더가 매긴 순서대로 트랜잭션을 수락하고 앙상블에 적용하자고 제안
리더는 쿼럼의 지지를 받아야한다. 두 부분집합이 독립적으로 실행되는 스플릿 브래인 상황을 피하기 위해서는 쿼럼은 반드시 겹쳐야 한다. 스플릿 브래인 상황에서는 일관성 없는 상태에 이르게 되어 클라이언트는 어떤 서버에게 연결되었는지에 따라 다른 결과를 얻는다.
각 서버는 LOCKING상태에서 시작한다. LOCKING상태는 새로운 리더를 선출하거나 이미 선출된 리더를 찾는 상태이다. 이미 리더가 존재한다면 다른 서버들은 어떤 서버가 리더인지 새로운 서버에게 알려준다.
서버들은 메시지를 통해 리더를 선출하는데, 리더 선출된 서버는 LEADING상태가 되고 앙상블의 다른 서버들은 FOLLOWING 상태가 된다.
서버는 LOCKING 상태가 되면 서버 식별자와 가장 최근에 실행된 zxid가 포함된 알림 메시지를 전달한다.
투표를 수신한 서버는 자신의 표를 다음 규칙에 따라 변경한다.
- voteId와 voteZxid를 투표를 수신한 서버의 현재표의 id와 zxid로 설정한다. 수신 서버의 값은 myZxid와 mySid이다.
- (voteZxid > myZxid ) or (voteZxid = myZxid AND voteId > mySid) 이면 투표를 유지
- 아닐경우, myZxid를 voteZxid로, mySid를 voteZxid로 할당해 서버의 표를 변경한다.
요약, 최근 데이터를 가진 서버가 투표에서 승리한다.
잽(The Zookeeper Atomic Broadcast Protocol) : 상태 변경사항 브로드캐스팅
팔로워는 쓰기 요청을 받으면 리더로 요청을 전달한다. 리더는 해당 요청을 투기적으로(speculatively) 실행하고 상태 변경 실행결과를 트랜잭션의 형태로 브로드캐스팅한다.
트랜잭션은 서버가 데이터트리에 적용해야할 변경 사항들의 집합으로 구성돼 커밋된다. 데이터트리는 주키퍼 상태를 담는 데이터 구조다.

트랜잭션이 커밋되었는지 서버가 판단하는 방법은 잽 프토콜을 사용한다.
- 리더는 PROPOSAL 메시지 p를 모드느 팔로워에게 보낸다.
- 팔로워는 p수신후 ACK 메시지를 리더에게 보내서 제안을 승인했다고 응답한다.
- 쿼럼의 승인을 받으면 리더는 팔로워에게 트랜잭션을 커밋하는 COMMIT 메시지를 보낸다.
제안 승인전 팔로워의 추가검사.
- 현재 따르고 있는 리더가 보낸 제안인지 확인
- 리더가 브로드캐스트한 것과 같은 순서대로 제안을 승인하고 트랜잭션을 커밋
잽은 두가지 속성을 보장한다.
- 리더가 T1과 T2를 순서대로 브로드캐스트하면 각 서버는 T2를 커밋하기 전에 반드시 T1을 커밋한다.
- 어떤 서버가 트랜잭션 T1과 T2를 순서대로 커밋하면 다른 모든 서버도 T2를 커밋하기 전에 T1을 커밋해야 한다.
에퍽(epoch)의 개념 : 시간이 지남에 따른 리더 역할의 변경을 나타내며, 서버가 리더 역할을 수행한 기간을 나타낸다.
리더가 두개가 존재할수 있는데, 잽은 리더가 하나만 있단것을 신뢰하지 않으며, 이를 해결하기 위해 다음사항을 요청한다.
- 선출된 리더는 이전 에퍽에서 커밋돼야할 모든 트랜잭션을 커밋하고 새로운 트랜잭션의 브로드캐스트를 시작한다.
- 두 서버는 동시에 쿼럼의 지지를 받지 못한다.
옵저버
리더의 제안을 커밋하는 점에서 팔로워와 공통점을 가지고 있지만, 투표과정에는 참여하지 않는다.
리더는 상태변경사항을 팔로워와 옵저버에게 알려주기 때문에 팔로워와 옵저버를 학습자라고 부른다.
옵저버를 ㄱ성하는 한가지 주요 이유는, 읽기 요청의 확장성 떄문이다. 옵저버를 추가하면 쓰기 처리량에 영향을 주지않고 더 많은 읽기 트래픽을 제공할 수 있다.
여러 데이터센터에 걸쳐 배포할때, 흩어진 참가자는 데이터 센터를 연결하는 회선의 지연 떄문에 주키퍼를 상당히 느리게 만들 수 있다. 이에대해 옵저버를 이용하면 투표에 사용하는 메시지를 사용하지 않으며 주키퍼를 좀더 빠르게 할 수 있다.
서버의 기본 구성
단독서버

PrepRequestProcessor : 클라이언트의 요청을 수락하고 트랜잭션을 생성.
SyncRequestProcessor : 트랜잭션을 디스크에 기록
FinalRequestProcessor : Request객체가 트랜잭션을 포함하고 있을경우 변경사항을 쿠피어 트리에 기록
리더서버
쿼럼 모드로 변경하는경우 서버 파이프라인은 약간 변경된다.
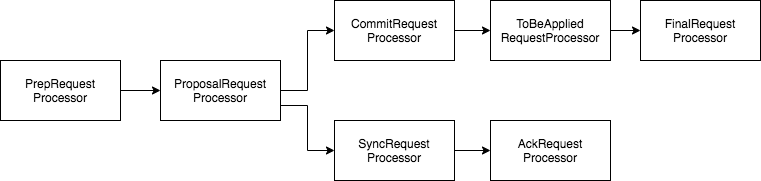
PrepRequestProcessor : 제안ㅇ르 준비하고 팔로워에게 보낸다. 모든 요청을 CommitRequestProcessor로 전달한다. 쓰기 요청은 추가적으로 SyncRequestProcessor에게 보낸다.
SyncRequestProcessor : 단독서버와 동일하게 트랜잭션을 디스크에저장, AckRequestProcessor를 동작후 종료.
AckRequestProcessor : 자신에게 승인을 생성하여 돌려주는 단순한 요청 처리기
CommitRequestProcessor : 충분한 승인을 받은 제안을 커밋, 리더 클래스가 승인을 처리하고 커밋된 요청을 CommitRequestProcessor 큐에 추가한다.
FinalRequestProcessor : 변경, 읽기 요청을 적용, 이 처리기 아에는 ToBeAppliedRequestProcessor라는 적용된 적용목록의 요소를 제거하는 처리기가 있다.
ToBeAppliedProcessor : FianlRequestProcessor가 요청을 처리하고 나면, ToBeAppliedRequestProcessor 는 목록의 요소를 제거한다.
팔로워와 옵저버 서버
하나의 연속된 처리기가 아니라, 클라이언트 요청, 제안, 커밋과 같은 다른 입력형태마다 파이프라인이 구성된다.

FollowerRequestProcessor : 요청을 CommitRequestProcessor로 전달하고, 쓰기 요청을 리더에게 추가 전달한다..
CommitRequestProcessor : 읽기 요청에대해서는 FinalRequestProcessor에 바로 전달하고 쓰기 요청에대해서는 커밋을 기다리고 FinalRequestProcessor로 전달한다.
SyncRequestProcessor : 요청을 처리하고 디스크에 로깅하고 SendAckRequestProcessor로 보낸다.
SendAckRequestProcessor : 리더의 제안을 승인한다.
로컬 저장소
서버는 트랜잭션 로그를 사용해서 트랜잭션을 영속한다.
주키퍼는 디스크에 쓰기 과정을 효과적으로 수행하기위해 커밋과 패딩이라는 트릭을 사용한다.
패딩 : 디스크블록을 파일에 미리 할당
스냅샷
주키퍼 데이터 트리의 복사본
서버와 세션
순서보장, 임시 zone, 와치는 세션과 밀접하게 연결된다.
팔로워서버는 자신에게 연결된 모든 클라이언트에 대한 세션정보를 전달한다. 서버는 세션 하트비트를 받아서 세션을 유지한다.
세션만료를 결정하는 두 가지
- 만료 큐 데이터 구조 : 만료오 관련된 세션 정보를 갖고 있다.
- 버킷 유지를 위해 리더는 시간을 expirationInterval 단위로 분할하고 각 세션을 해당 세션의 만료시간 이후에 만료되는 버킷에 할당한다.
와치
와치는 한번만 트리거되고, 읽기 작업을 할 때 설정할 수 있다. 서버가 트리거한 와치는 클라이언트로 전파된다.
- 와치는 메모리에서만 유지되고 디스크에 기록되지 않는다. 클라이언트와 서버의 연결이 끊어지면, 모든 클라이언트의 와치는 서버의 메모리에서 제거된다.
- 클라이언트의 라이브러리는 처리되지 않은 와치를 관리하기 때문에 새롭게 연결된 서버에 처리되지 않은 와치를 재설정 할 것이다.
'IT > zookeeper' 카테고리의 다른 글
| 주키퍼를 모니터링 하기위한, 포레터 단어(four-letter word) (0) | 2020.09.25 |
|---|---|
| 주키퍼 개념 읽어보기~ (0) | 2020.09.12 |
| 주키퍼 공부의 시작 ㅠ (0) | 2020.09.11 |
