최근 주키퍼 API를 이용해서 집에서 시간이 날때마다 이것저것 해보고있는데, 명령어도 간단해서 너무 유익하다. 그러나, 주키퍼의 설명을 다룬 정리글을 쓰려고 했는데, 깜빡하고 책을 읽기만 하고 정리해둔게 하나도 없어 막막해하던 즈음, 이전에 주키퍼 영문판을 보면서 정리해둔 글을 발견하였다.
그 당시에 책을 읽지 않고 오직 레퍼런스(영문)을 한글로 옮겨적기만 한 글이지만, 정리가 되리라 생각되고, 이렇게 다시읽어보니 그때 이해가 되지 않던 글들이 이해가 되는 느낌이다.
다음은 주키퍼 사이트에서 설명하는 주키퍼의 특징이다.
Apache ZooKeeper
주키퍼란
주키퍼는 설정정보, 네이밍, 분산동기화제공, 그룹서비스를 제공하는 중앙화된 서비스이다. 주키퍼에서 제공하는 이러한 기능들은 분산 어플리케이션에서 사용되고있다. 매번 수정작업을 거치고 있는데, 수정작업의 경우 버그를 고치는 것과 레이스 컨디션(두 개 이상의 concurrent한 스레드들이 공유된 자원에 접근하려고 할 때 동기화 메커니즘 없이 접근하려고 하는 이런 상황) 을 고치는 작업을 진행한다.
이러한 종류의 서비스를 구현을 하는데 어려움이 있기에 어플리케이션들은 처음에는 보통 이러한 서비스들을 사용하지 않지만 이러한 것들이 변화와 관리를 불안정하게 한다. 심지어 완벽하게 구현이 되더라도, 다른 어플리케이션들이 배포되었을때 관리의 복잡도를 높이게 된다.
(이 부분은 프로그램의 규모가 커져 클러스터의 구조를 가지려 할 때 중요한 영향을 끼친다고 생각된다.
Zookeeper 개요
분산 어플리케이션을 위한 분산 조절 서비스
주키퍼는 분산 어플리케이션을 위한 오픈소스 분산 서비스이다. 분산 응용 프로그램이 동기화, 구성 유지 보수, 그룹 및 이름 지정을 위한 상위 레벨 서비스를 구현하기 위해 구축할 수 있는 간단한 기본 세트를 제공한다. 주키퍼는 프로그래밍 하기 쉽게 디자인 되었고 파일 시스템의 트리형 디렉토리 구조와 같은 데이터 모델을 사용하였다. 주키퍼는 자바로 동작하며, 자바, C에 모두 바인딩 되어있다.
조정 서비스들은 제대로 맞기 어렵다고 악명이 높다. 특히 레이스 컨디션이나 데드락이 발생하기 쉽다. Zookeeper를 만들게된 동기는 조정서비스를 구현하는 수고를 덜어주는 것이다.
디자인 목표들
주키퍼는 간단하다.
(정말 요 며칠간 개념을 숙지하고 api, zookeeper client를 사용해 봤을때 그냥 리눅스 파일시스템과 비슷하다고 느꼈고 그냥 파일시스템을 참조하여 읽고 쓰는게 다라고 느낄 정도로 간단한 시스템이라고 느꼈다. 예를들면 java의 File 클래스를 사용하는 느낌)
주키퍼를 사용하면 분산 프로세스가 표준 파일시스템과 유사하게 구성된 공유 계층 네임 스페이스를 통해 서로 조정할 수 있다. 네임스페이스는 znodes라고 불리는 data register들로 구성되어 있고, 이것들은 파일, 폴더들과 유사합니다.
스토리지용으로 설계된 일반적인 파일시스템과 달리, 주키퍼는 인메모리 기반이고 이러한 것은 높은 처리량과 낮은 대기시간을 달성할 수 있습니다. (한마디로 빠르다!)
주키퍼구현은 고성능, 고가용성, 엄격하게 순서화된 접근에 프리미엄을 제공합니다. 주키퍼의 성능측면은 대규모, 분산시스템에서 사용할 수 있음을 의미합니다. 안정성 측면에서는 단일 장애에 대한 문제점(여러대의 서버로 이루어진 시스템에서 하나의 서버만 멈춰도 전체가 멈추는 문제)을 해소하는데 도움이 된다. 엄격한 처리 순서는 정교화 동기화 구현이 클라이언트에서 구현될 수 있다는 것을 의미합니다.
주키퍼는 복제되어있다.
조정된 분산 프로세스와 마찬가지로 주키퍼 자체는 앙상블 이라는 일련의 호스트를 통하여 복제가 됩니다. (이들중 하나가 고장나더라도 주키퍼 서비스는 멈추지 않으므로 고가용성을 제공한다!)
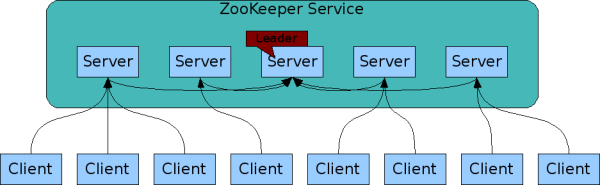
주키퍼를 구성하는 서버들은 각자를 알아야 한다. 서버들은 인메모리 상태의 이미지와 트랜잭션로그들 그리고 스냅샷들은 영구저장소에 관리합니다. 대부분의 서버를 사용할 수 있는 한 주키퍼 서비스를 사용할 수 있습니다.
클라이언트(여기서 클라이언트란 주키퍼 API를 사용하여서 주키퍼에서 정보를 사용(읽기, 쓰기)하는 프로그램을 말한다)는 단일 Zookeeper 서버에 연결됩니다(어떠한 서버에 연결되든지 주키퍼 앙상블에 속한 주키퍼 서버들은 모두 동일한 데이터를 갖는것을 보장한다).
클라이언트는 요청을 보내고 응답을 받고 원하는 이벤트를 얻고 heart beat를 보내서 TCP 연결을 유지합니다.
주키퍼는 순서화되어있다.
주키퍼는 모든 주키퍼 트랜젝션에 순서를 나타내는 숫자로 각각의 업데이트에 스탬프를 찍습니다. 후속 작업은 상위 레벨의 추상화를 구현하기 위해 순서를 사용할 수 있습니다.
주키퍼는 빠릅니다.
주키퍼는 읽기 작업에서 특히 빠릅니다. 주키퍼 응용프로그램은 수천 대의 컴퓨터에서 실행되며, 쓰기보다 읽기가 일반적인 곳에서 약 10:1의 비율로 가장 잘 수행됩니다.
데이터 모델이 계층적 네임스페이스이다. (리눅스 파일시스템과 비슷하다!)
주키퍼에 포함된 네임스페이스는 일반적인 파일ㅇ시스템과 유사하다. 이름은 슬래시(/)로 구분된 일련의 경로 요소입니다. 주키퍼의 네임스페이스에 있는 모든 노드는 경로로 구분되어 있습니다.
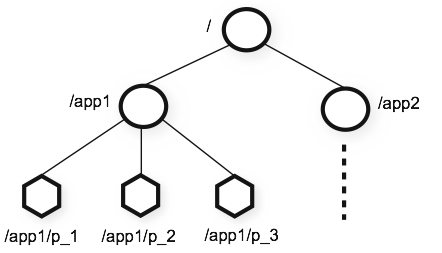
[ 주키퍼의 계층적인 네임스페이스 ]
노드와 임시노드
일반적인 파일시스템과는 다르게, 주키퍼 네임스페이스에 있는 각각의 노드는 자식뿐만 아니라 이와 관련된 데이터가 있을수도 있습니다. 파일도 디렉토리가 될 수 있는 파일 시스템을 갖는 것과 같습니다. (주키퍼는 상태정보, 설정, 위치정보 등의 조정 데이터를 저장하도록 설계되었으므로 각 노드에 저장된 데이터들은 바이트에서 킬로바이트 규모로 작습니다.)
Znode는 캐시 유효성 검증 및 조정된 업데이트를 허용하기 위해 데이터 변경, ACL(Access Control List)변경 및 생성시간에 대한 버전 번호를 포함하는 통계 구조를 유지합니다. znode의 데이터가 변경될 때마다 버전 번호가 증가합니다. 예를 들어, 사용자가 데이터를 검색할때 또한 데이터의 정보까지 받게 됩니다.
네임 스페이스의 각 znode에 저장된 데이터는 원자 단위로 읽고 씁니다. 읽기는 znode와 연관된 데이터 바이트를 가져오고 쓰기는 모든 데이터를 대체합니다. 각 노드에는 누가 무엇을 할 수 있는지를 제어하는 액세스 제어 목록(Access Control List)가 있습니다.
주키퍼는 또한 임시노드라는 개념을 가지고 있습니다. znode는 znode를 작성한 세션이 활성 상태인 이상 존재합니다. 세션이 종료되면 삭제됩니다.
조건부 업데이트와 watches
주키퍼는 watches라는 개념을 제공한다. 사용자는 watch를 znode에서 지정할수 있다. znode가 변화할때 watchs는 znode가 트리거되고 제거된다. watch가 트리거될때, 사용자는 znode가 바뀌었다고 말하는 패킷을 받게될 것이다. 만약 클라이언트와 하나의 주키퍼 서버사이의 연결이 끊어지면, 클라이언트는 로컬 알림을 받게 된다.
보증
주키퍼는 매우 빠르고 간단하다. 비록 주키퍼의 목적이 동기화와 같이 좀 복잡한 서비스를 구축하기 위한 기초가 되지만, 그것은 보장 세트를 제공합니다.
create : tree에 위치한 노드를 생성한다.
delete : 노드를 삭제한다.
exists : 해당 장소에 노드가 있는지 테스트한다.
get data : 노드로부터 데이터를 읽는다.
set data : 노드에 데이터를 쓴다.
get children : 노드의 자식리스트를 검색한다.
sync : 데이터가 전파될때까지 기다린다.
구현
주키퍼 구성요소들은 높은레벨의 주키퍼서비스의 구성요소들을 보여준다. 요청 프로세서를 제외하고 Zookeeper 서비스를 구성하는 각 서버는 각 구성 요소의 자체 복사본을 만듭니다.
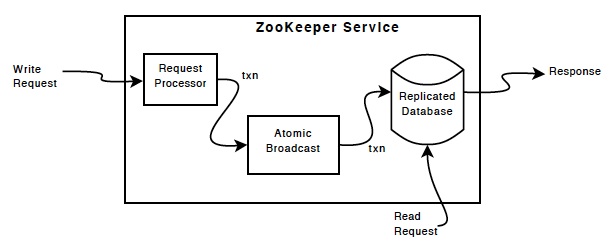
복제된 데이터베이스는 in-memory 데이터베이스이고 모든 데이터는 트리형태로 저장되어있다. 수정사항들은 디스크에 로그형태로 저장되고 회복을 위해 쓰인다. 그리고 쓰기는 in-memory 데이터베이스에 적용되기 전에 디스크에 직렬화 됩니다.
모든 주키퍼 서버는 클라이언트를 서비스합니다. 클라이언트들은 정확히 하나의 서버에 연결되고 요청을 전송합니다. 읽은 요청들은 각 서버의 로컬 복제품들로 부터 서비스를 받습니다. 서비스의 상태를 바꿔주는 요청, 쓰기요청은 계약 프로토콜에 의해 처리됩니다.
계약프로토콜의 일부로 클라이언트로 부터 모든 쓰기요청들은 리더라고 불리는 단일 서버로 전달됩니다. 팔로워라고 불리는 남아있는 주키퍼 서버들은 메시지제안을 리더로부터 받고, 메시지 전달에 동의합니다. 메시징 계층은 장애발생시 리더를 교체하고, 리더와 팔로워를 동기화합니다.
주키퍼는 커스텀 원자 메시징 프로토콜을 사용한다. 메시지 계층이 원자단위여서, 주키퍼는 로컬 복제본이 분기되지 않도록 보장할수 있습니다. 리더는 쓰기 요청을 받으면 쓰기가 적용될 때 시스템 상태를 계산하여 이 새로운 상태를 캡쳐하는 트랜잭션으로 변환합니다.
사용
주키퍼에 접근하는 프로그래밍 인터페이스는 의도적으로 간단합니다. 간단하지만, 이 기능을 사용하면 동기화 기본요소, 그룹 멤버쉽, 소유권 같은 고차원의 기능들을 구현할 수 있습니다.
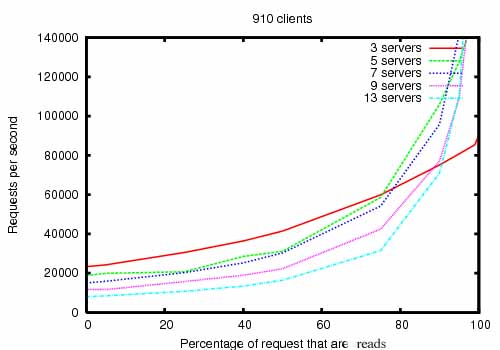
성능
주키퍼는 높은 성능을 갖도록 디자인 되어있다. 야후의 주키퍼 개발팀에따르면, 특히 읽기수가 쓰기보다 많은 어플리케이션에서 높은 성능을 보여줍니다. 쓰기는 모든 서버의 상태를 동기화 하는것이 포함되므로.(일반적인 조정 서비스의 경우 읽기수가 쓰기수를 초과합니다.)
'IT > zookeeper' 카테고리의 다른 글
| 주키퍼를 모니터링 하기위한, 포레터 단어(four-letter word) (0) | 2020.09.25 |
|---|---|
| 주키퍼의 내부구조 (0) | 2020.09.20 |
| 주키퍼 공부의 시작 ㅠ (0) | 2020.09.11 |
