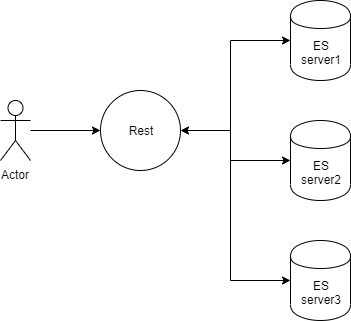
몇일에 걸쳐 Elasticsearch의 데이터 처리에 대해 공부를 했다. ElasticSearch에서 말하고 있는 데이터처리란 우리가 알고있는 CRUD 작업. 즉, 데이터의 Create, Retrieve, Update, Delete에 대한 작업을 지칭한 것이다. ElasticSearch에서의 CRUD 요청은 ElasticSearch서버에 REST 요청을 하면서 이루어 진다.
이 대목에서 과거 이전 회사의 다른 팀원이 ElasticSearch에 대해 발표하였을때 또다른 팀원이 질의하였던 것이 생각이난다. "Rest요청 말고는 데이터 처리요청방법이 없는가요?" 였는데, "네 Rest 요청밖에 없습니다."는 것이었다.
왜 Rest요청으로 밖에 데이터를 처리하지 못하겠는가 Rest처리 바로 뒤의 처리과정을 알면 그 중간에서 데이터 처리를 하면 되겠지만, 내 개인적인 생각으로는 Rest요청을 전처리로 받고 후처리로 분산처리, 색인 또는 검색작업이 일련의 순서대로 진행되기 때문에 Rest요청으로 처리를 하면 뒤의 과정을 생각하지 않아도 되서 효율적이라고 생각을 하게된다.
Rest처리로 인한 HTTP통신속도의 문제도 있겠지만 ElasticSearch의 분산처리 및 색인, 검색등을 알아서 처리해주는 점을 감안한다면(?) HTTP 속도의 문제는 미미하다는 생각이 든다.다음은 내가 생각한 ElasticSearch의 데이터 처리 구성도이다.(틀릴수도 있다)

내가 이해한게 틀릴수 있으니 차후 공부하면서 잘못 받아들인 지식이 있으면 수정하도록 하여야 할 것이다. 자, 그럼 데이터처리관련 공부하면서 정리해놓은 글과 에로사항을 보겠다.
1. 학습파트 : 데이터 처리
2. 학습목표 : 데이터 구조를 살펴보고 데이터의 입력, 출력, 삭제, 검색 명령을 실행해보기
1. 엘라스틱서치의 데이터 구조
인덱스(Index), 타입(Type), 도큐먼트(Document)의 단위로 이루어짐
도큐먼트(Document) : 엘라스틱서치의 데이터가 저장되는 최소단위
타입(Type) : 여러개의 도큐먼트의 모임
인덱스(Index) : 여러개의 타입의 모임, 인덱스는 샤드와 복사본으로 나누어진다.
(기본값으로 샤드는 5, 복사본은 1개의 값을 갖는다.)
엘라스틱서치와 관계형 Database를 비교하면 다음의 표와 같다.
|
관계형 DB |
엘라스틱서치 |
|
데이터베이스 |
인덱스 |
|
테이블 |
타입 |
|
행 |
도큐먼트 |
|
열 |
필드 |
|
스키마 |
매핑 |
Centos에서 ElasticSearch로의 Rest 요청 명령어(Curl 말고도 HTTP요청 방법이 있다면 그것을 사용하면 될 것이다.
$ curl -X{메서드} http://host:port/{인덱스}/{타입}/{도큐먼트 id} -d '{데이터}'
인덱스는 _all 명령어로 모든 인덱스를 표현할 수 있으며, 어떤 명령은 인덱스와 타입에 콤마(,)와 와일드카드 문자를 사용하여 다중 표현이 가능하다.
|
HTTP Method |
CRUD |
SQL |
|
GET |
READ |
SELECT |
|
PUT |
UPDATE |
UPDATE |
|
POST |
CREATE |
INSERT |
|
DELETE |
DELETE |
DELETE |
2. 데이터 처리
2.1 데이터 추가, 검색
PUT또는 POST로 도큐먼트를 생성할 수 있는것으로 보이는데 차이점은 PUT의경우 id값을 URL에 넣지 않으면 에러가 발생하고 POST의 경우 임의의 id값을 생성한다.
다음은 인덱스(books), 타입(book), ID(1)을 지정하여 하나의 문서를 생성하는 예제이다. 책과 다른점은 PUT요청이나 POST요청시에는 ElasticSearch7에서는 -H 를 지정하여 Content Type을 지정해 줘야 한다. application/xml이나 text/xml도 지원하나 싶어서 테스트를 해보았는데 해당 데이터는 지원하지 않는 것을 보인다.
일단 아래의 명령어를 실행시켜서 데이터의 입력 및 출력이 제대로 되는지 확인한다.
<code />
$ curl -XPUT http://localhost:9200/books/book/1 -H "Content-Type: application/json" -d '
{
"title":"Elasticsearch Guide",
"author":"Kim",
"date":"2014-05-01",
"pages":250
}'
$ curl -XGET http://localhost:9200/books/book/1
위의 명령어를 실행해 보면 출력이 제대로 되는것을 볼 수 있다.
출력된 예제의 데이터를 보면 다음과 같은 값들이 추가되었다.
index, type, id, version, seq_no, primary_term, found, source
이 중, source의 경우 내가 입력한 값이고 그 외의 값들은 데이터의 상태를 나타내는 메타데이터로 보인다.
{인덱스}/{타입}/{도큐먼트 ID}가 동일한 값에 대하여 POST나 PUT을 이용하여 데이터를 갱신시키면 _version값이 증가한다.
그런데 뭔가 데이터가 이쁘게 나오지 않는 것 같다. 데이터를 이쁘게 나오게 하기위해 pretty=true 인자를 전달하면 데이터가 이쁘게 정렬되어 출력된다.
$ curl -XGET http://localhost:9200/books/book/1?pretty=true
2.2 데이터 삭제
#문서삭제
$ curl -XDELETE http://localhost:9200/{인덱스}/{타입}/{아이디}
#인덱스 삭제
$ curl -XDELETE http://localhost:9200/{인덱스}
책에는 타입단위까지 지울 수 있다고 나와있으나 테스트 결과 타입은 지워지지 않는 것으로 보인다.
2.3 데이터 갱신
<c++ />
# category필드의 값을 ICT로 변환 없으면 추가
$ curl -XPOST localhost:9200/books/book/1/_update -H "Content-Type:application/json" -d '
{"doc":{"category":"ICT"}}'
# pages필드값에 50을 더함
$ curl -XPOST localhost:9200/books/book/1/_update -H "Content-Type:application/json" -d '
{"script" :"ctx._source.pages +=50"}'
# author필드의 값을 배열로 바꾸고 값을 ICT추가
$curl -XPOST localhost:9200/books/book/1/_update -H "Content-Type:application/json" -d '
{"doc":{"author":["ICT"]}}'
# pages필드값에 1을 더함
$ curl -XPOST localhost:9200/books/book/1/_update -H "Content-Type:application/json" -d '{
"script":{
"source":"ctx._source.pages++"
}'
# author값에 KIM을 더함.(위의 예제에서 author필드가 배열로 바뀌었으므로 ["ICT","KIM"] 으로 저장
# 책의 내용과 상이한 부분이 많은 예제였음 특히 author카테고리(배열)에 추가할땐 +가 아닌 add를 사용
$ curl localhost:9200/books/book/1/_update?pretty=true -H "Content-Type:application/json" -d '{
"script":{
"source":"ctx._source.author.add(params.new_author)",
"lang":"painless",
"params":{
"new_author":"KIM"
}
}
}'
2.4 if 조건문을 이용한 데이터 처리
<c++ />
#만약 author에 KIM이 포함되어 있으면 pages를 100으로, 아니면 200으로 값을 바꿈
curl -XPOST localhost:9200/books/book/1/_update?pretty=true -H 'Content-Type:application/json' -d '{
"script":
{
"source":"if(ctx._source.author.contains(params.auth)){ ctx._source.pages=100} else{ ctx._source.pages=200}",
"params":{"auth":"KIM"}
}
}'
#만약 pages의 값이 700이면 100을 증가, 아니면 200을 증가
curl -XPOST localhost:9200/books/book/1/_update?pretty=true -H 'Content-Type:application/json' -d '{
"script":
{
"source":"if(ctx._source.pages==700){ ctx._source.pages+=100} else{ ctx._source.pages+=200}",
"params":{"auth":"KIM"}
}
}'
#만약 pages의 값이 page_cnt 이하이면 삭제, 아니면 아무동작안함
curl -XPOST localhost:9200/books/book/1/_update?pretty=true -H 'Content-Type:application/json' -d '{
"script":
{
"source":"if(ctx._source.pages <= params.page_cnt){ ctx.op=\"delete\"} else{ctx.op =\"none\"}",
"params":{"page_cnt":100}
}
}'
#upsert : 해당 도큐먼트가 존재하지 않을 때 정의된 도큐먼트를 생성하는 명렁
curl -XPOST localhost:9200/books/book/1/_update?pretty=true -H 'Content-Type:application/json' -d '
{
"script":
{
"source" : "ctx._source.count+=params.count",
"params" : {"count" : 1}
},
"upsert" : {
"count" : 0
}
}'
2.5 파일을 이용한 데이터 처리
<html />$ curl -X{메서드} http://host:port/{인덱스}/{타입}/{도큐먼트 id} -d @{파일명} $ echo '{ "title":"elasticsearch book", "author":["KIM", "LEE"], "date" : "2019-11-04", "pages" : 300 }' > book_1 $ echo '{ "doc":{ "category":"ICT" } }' > update_1 $ curl -XPOST localhost:9200/books/book/1/_update -H "Content-Type:application/json" -d @update_1
2.6 벌크(_bulk) API를 이용한 배치작업
엘라스틱서치에서는 여러 명령을 한꺼번에 실행할 수 있는 배치작업을 위한 벌크 API를 제공한다. 입력할 데이터를 모아 한꺼번에 처리하므로 데이터를 각각 처리하고 결과를 반환할 때보다 속도가 매우 빠르다.
$ curl -XPOST http://host:port/{인덱스}/{타입}/_bulk -H "Content-Type:application/json" -d '{데이터}' or @{파일명}
$ curl -XPOST http://host:port/{인덱스}/_bulk -H "Content-Type:application/json" -d '{데이터}' or @{파일명}
$ curl -XPOST http://host:port/_bulk -H "Content-Type:application/json" -d '{데이터}' or @{파일명}
2.6.1 REST 요청을 통한 벌크작업
$ curl -XPOST localhost:9200/_bulk?pretty=true -H "Content-Type:application/json" -d '
{ "index" : {"_index" : "books", "_type" : "book", "_id" : "1" } }
{"title":"Elasticsearch Guide1", "author" : "Kim", "pages" : 250}'
$ curl -XPOST localhost:9200/_bulk?pretty=true -H "Content-Type:application/json" -d '
{ "create" : {"_index" : "books", "_type" : "book", "_id" : "1" } }
{"title":"Elasticsearch Guide1", "author" : "Kim", "pages" : 250}'
create, index 둘다 도큐먼트가 생성되지만, create의 경우엔 중복되어 호출할 경우 dupicate오류가 발생하고 index는 덮어쓴다.
2.6.2 파일을 이용한 벌크작업
[파일명 : bulk_1]
<html />{"delete" : {"_index":"books", "_type":"book","_id":"1"}} {"update":{"_index":"books","_type":"book","_id":"2"}} {"doc":"{"date" : "2014-05-01"}} {"create" : {"_index" : "books","_type":"book" ,"_id":"3"}} {"title":"Elasticsearch Guide II","author":"Park","pages":400}}
$ curl -XPOST localhost:9200/_bulk?pretty=true -H "Content-Type:application/json" --data-binary @bulk_1
2.6.3 벌크 UDP API
Elasticsearch 공식 페이지의 문서를 살펴보니 UDP API는 없어진 것으로 보인다.
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk-udp.html
외부에서 접근이 안되는 문제 발생
ElasticSearch의 데이터처리의 다양한 방법을 살펴보았다. 데이터 처리를 공부하면서 느낀점은 책과 상이해진 부분이 상당히 많다는 점이다. 내용의 상이함으로 인해 책을 한장 한장 넘기기 힘들었지만 그래도 리서치를 해가면서 기능이 수행되도록 때까지의 과정에서 개념에 대해 더 상세히 파고들 수 있었고 이로인해 지식이 정리되는 듯한 느낌이 있어 그렇게 나쁘지만은 않은 듯 하다.
다음에는 ElasticSearch의 시스템 구조에 대해 알아보도록 해야겠다.
'IT > ElasticSearch' 카테고리의 다른 글
| Elasticsearch Nori 플러그인 설치하기 (0) | 2021.09.15 |
|---|---|
| Elasticsearch 단위테스트를 위한 testContainer사용하기 (0) | 2021.06.01 |
| ElasticSearch 설치 (0) | 2019.10.31 |
| ElasticSearch 시작 (0) | 2019.10.30 |
