아파치 스파크,, 2016년 10월경에 회사에서 퇴직할 당시 가끔씩 들려오던 이름이다. (마치 지금의 스프링 부트나 하이버네이트 처럼) 이러한 것들을 머릿속에서 지우고 유한화학 IT 매니저로 2년 6개월간 일하고 다시 개발업계로 돌아온 지금 이러한 기술들은 현재 현업에서 주로 쓰이고 있는것으로 보인다.
스프링 부트나 하이버네이트의 경우 헬창닷컴을 개발하면서 사용해 보았기에 친숙하지만 스파크의 경우 그렇지 않다. 스파크는 지금 다른 부서에서 구축 및 운용할 것으로 보이는데 공부하고자 하는 이유는 이 부서가 우리와 협업을 하는 부서이기 때문이고 그렇기 때문에 적어도 스파크의 기본정도는 알고 있어야 예의라는 생각이 들어서이다. 그렇기에 매일같이 적어도 30분은 스파크에 대한 책을 읽거나 고민을 하고 일주일에 블로그 포스팅 하나 이상을 하는 목표를 갖고 있다.
스파크란?
범용적이면서도 빠른 속도로 작업을 수행할 수 있도록 설계된 클러스터용 연산 플랫폼이다. (여기서 클러스터란 여러개의 컴퓨터를 하나의 컴퓨터처럼 사용하는 기법을 말한다.)
속도의 측면 - 맵리듀스 모델을 대화형 명렁어 쿼리나 스트리밍 처리등이 가능하게 하였다.
범용성 측면 - 배치 애플리케이션, 반복 알고리즘, 대화형 처리, 스트리밍 같은 다양한 작업을 동시에 커버할 수 있도록 설계
접근성 측면 - 파이썬, 자바, 스칼라, SQL API 및 강력한 라이브러리를 내장 지원
통합된 구성
SQL이나 머신러닝 같은 다양한 워크로드에 특화된 여러 고수준 컴포넌트를 실행할 수 있도록 해준다. 그리고 컴포넌트들은 일반 소프트웨어에서 라이브러리를 갖다 쓰듯이 연동해서 쓸 수 있도록 상호 호환적으로 설계되었다.
통합된 구성이 갖는 강점
- S/W 구성에 포함된 라이브러리, 컴포넌트들이 하위 레이어의 성능향상에 직접 영향을 받는다.
- 서로 다른 데이터 처리 모델을 합쳐서 하나의 애플리케이션을 만들 수 있다.
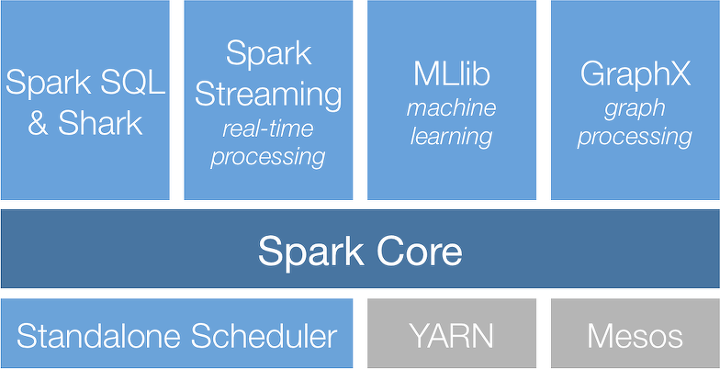
스파크 코어 : 작업 스케줄링, 메모리 관리, 장애 복구, 저장 장치와의 연동등 기본적인 기능들로 구성됨.
스파크 SQL : 정형 데이터를 처리하기 위한 스파크의 패키지.
스파크 스트리밍 : 실시간 데이터 스트림을 처리 가능하게 해주는 스파크 컴포넌트
MLlib : 다양한 타입의 머신러닝 알고리즘, 모델평가 및 외부 데이터 불러오기 기능 제공
그래프 X : 그래프를 다루기 위한 라이브러리
클러스터 매니저 : 한 노드에서 수천 노드까지 효과적으로 성능을 확장 가능하도록 하는 기능 제공
역사
2009년
UC 버클리 RAD 연구실의 연구프로젝트로 시작. 하둡의 맵리듀스가 반복적 대화형 연산에는 비효율적이라는 것을 인지하여 인메모리 저장장치 및 효과적인 장애복구 지원 개념에 기반하여 대화형 쿼리와 반복성 알고리즘에 빠르게 반응하도록 설계
2010년
2010년 3월에 처음 오픈소스화
2011년
샤크나 스파크 스트리밍 같은 고수준 컴포넌트 개발
